Distribusi data adalah konsep penting dalam statistik yang menggambarkan bagaimana data tersebar atau terdistribusi dalam suatu kumpulan observasi. Memahami jenis-jenis distribusi data sangat penting karena akan menentukan metode analisis statistik yang tepat.
Dalam analisis data, distribusi membantu kita memahami pola, kecenderungan, serta kemungkinan variasi yang terjadi pada data.
Artikel ini membahas berbagai jenis distribusi data yang umum digunakan dalam statistik dan penerapannya dalam penelitian maupun data science.
Apa Itu Distribusi Data?
Distribusi data adalah pola penyebaran nilai dalam suatu dataset. Distribusi menunjukkan:
bagaimana data tersebar
apakah data simetris atau tidak
apakah data condong ke kiri atau ke kanan
apakah data mengikuti pola tertentu
Distribusi biasanya divisualisasikan menggunakan histogram atau kurva probabilitas.
Jenis-Jenis Distribusi Data
Berikut adalah distribusi data yang paling sering digunakan dalam statistik:
1️⃣ Distribusi Normal
Distribusi normal adalah distribusi berbentuk lonceng (bell curve) yang simetris.
Ciri-ciri:
mean, median, dan modus berada di tengah
kurva simetris
banyak data berkumpul di sekitar rata-rata
Distribusi normal sering digunakan dalam:
uji hipotesis
uji Z
uji T
ANOVA
Contoh: tinggi badan, skor IQ, nilai ujian.
Pelajari lebih lanjut mengenai Distribusi Normal disini.
2️⃣ Distribusi Uniform
Distribusi uniform adalah distribusi di mana setiap nilai memiliki peluang yang sama.
Ciri-ciri:
Contoh: hasil lemparan dadu yang adil.
Pelajari lebih lanjut mengenai Distribusi Uniform disini.
3️⃣ Distribusi Binomial
Distribusi binomial digunakan untuk data dengan dua kemungkinan hasil (ya/tidak, sukses/gagal).
Ciri-ciri:
Contoh:
Pelajari lebih lanjut mengenai Distribusi Binomial disini.
4️⃣ Distribusi Poisson
Distribusi Poisson digunakan untuk menghitung jumlah kejadian dalam interval waktu atau ruang tertentu.
Ciri-ciri:
Contoh:
Pelajari lebih lanjut mengenai Distribusi Poisson disini.
5️⃣ Distribusi Eksponensial
Distribusi eksponensial digunakan untuk mengukur waktu tunggu antar kejadian.
Ciri-ciri:
Contoh:
waktu tunggu pelanggan
waktu kerusakan mesin
Pelajari lebih lanjut mengenai Distribusi Eksponensial disini.
6️⃣ Distribusi Chi-Square
Distribusi chi-square digunakan dalam pengujian hipotesis, terutama untuk data kategorikal.
Ciri-ciri:
Pelajari lebih lanjut mengenai Distribusi Chi-Square disini.
7️⃣ Distribusi T (Student’s t Distribution)
Distribusi t digunakan ketika ukuran sampel kecil dan varians populasi tidak diketahui.
Ciri-ciri:
Pelajari lebih lanjut mengenai Distribusi T disini.
8️⃣ Distribusi F
Distribusi F digunakan dalam analisis varians (ANOVA).
Ciri-ciri:
Pelajari lebih lanjut mengenai Distribusi F disini.
Mengapa Memahami Distribusi Data Itu Penting?
Mengetahui distribusi data membantu dalam:
menentukan metode analisis yang tepat
memilih uji statistik yang sesuai
memahami karakteristik data
menghindari kesalahan interpretasi
membuat keputusan berbasis data
Jika salah memahami distribusi, hasil analisis bisa menjadi tidak valid.
Perbedaan Distribusi Diskrit dan Kontinu
Distribusi Diskrit:
data berupa angka bulat
contoh: jumlah pelanggan
Distribusi Kontinu:
Bagaimana Mengetahui Distribusi Data?
Beberapa cara yang umum digunakan:
melihat histogram
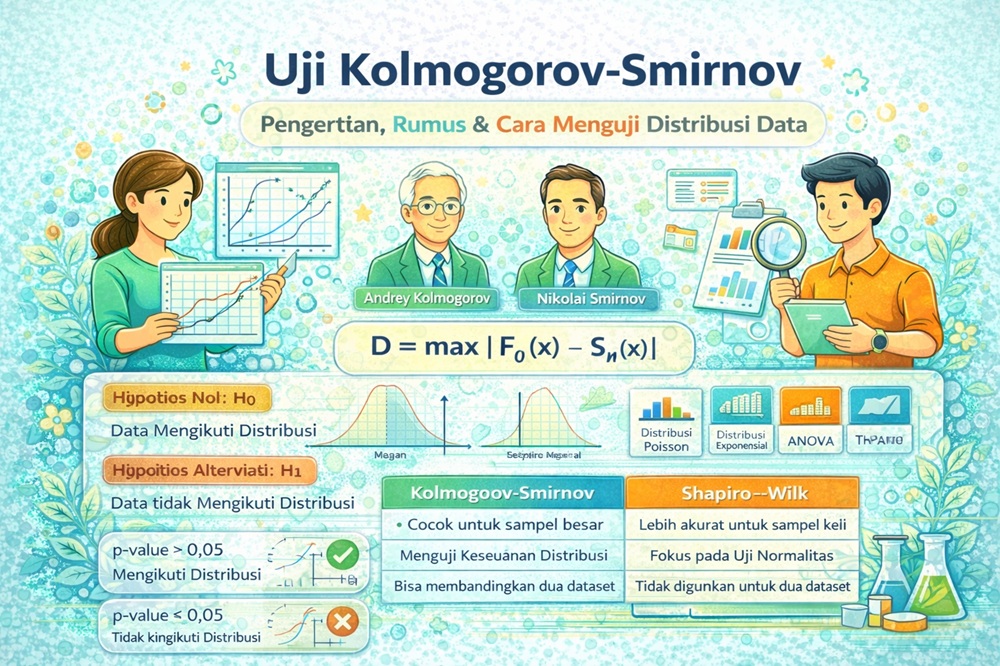
uji normalitas (Shapiro-Wilk, Kolmogorov-Smirnov)
melihat skewness dan kurtosis
menggunakan software statistik
Kesimpulan
Jenis-jenis distribusi data dalam statistik sangat beragam, mulai dari distribusi normal, binomial, Poisson, hingga distribusi chi-square dan F.
Memahami distribusi data adalah langkah awal dalam analisis statistik yang benar. Dengan mengetahui pola penyebaran data, kita dapat memilih metode analisis yang tepat dan menghasilkan kesimpulan yang lebih akurat.
Distribusi data bukan hanya teori, tetapi fondasi penting dalam penelitian, data science, dan pengambilan keputusan berbasis data.
Jika Anda ingin memanfaatkan Distribusi Data untuk analisa data yang lebih cerdas dan berdampak nyata, kami siap menjadi partner terpercaya Anda.